
近日,CVPR 2026(國際計算機視覺與模式識別會議)召開,理想汽車共有12篇論文入選。CVPR是計算機視覺與模式識別領域的頂級學術會議,與ICCV(國際計算機視覺大會)、ECCV(歐洲計算機視覺國際會議)並稱為計算機視覺領域三大頂級會議,具有極高的學術影響力。理想汽車此次入選12篇論文,涵蓋多模態感知、端到端規劃、世界模型、強化學習、認知模型及語言智慧等多個核心領域,系統性展現了理想汽車持續深耕具身智慧技術領域的研究實力。
從感知到決策 帶來全新技術範式
感知能力是具身智慧的認知起點。在多模態感知領域,理想汽車SparseWorld-TC論文被收錄為Oral(大會口頭報告),SparseWorld-TC全新架構突破了傳統方法依賴鳥瞰圖投影和離散化token表示的雙重瓶頸,直接從原始圖像特徵端到端預測多幀未來三維場景佔據情況。該方法採用稀疏佔據表示,使Transformer能夠更高效地建模時空依賴關係,在nuScenes基準上的1至3秒佔據預測任務中達到當前最優性能,並在任意未來軌跡條件下保持較高精度,為智慧輔助駕駛提供更精準的環境預判能力。
在端到端規劃領域,理想汽車提出SGDrive框架,將駕駛理解分解為“場景-交通參與體-目標”的層級結構,這一設計與人類駕駛認知方式高度對應:駕駛員首先感知整體環境,繼而識別關鍵交通參與體及其行為,最後形成短期目標並執行動作。SGDrive通過結構化的時空表示彌補了通用視覺語言模型在駕駛場景中的認知空缺,在NAVSIM基準上的純視覺方案中取得當前最優性能,驗證了層級化知識結構對於提升智慧輔助駕駛規劃能力的有效性。
在強化學習領域,理想汽車提出PlannerRFT框架,解決了基於擴散模型的規劃器在強化微調過程中難以生成多模態、場景自適應軌跡的核心難題。PlannerRFT採用雙分支優化策略,在不改變原始推理流程的前提下,同時優化軌跡分佈並自適應引導去噪過程。為支持大規模並行學習,理想汽車同步開發了nuMax倣真器,其軌跡推演速度較原生nuPlan提升10倍,為強化學習在智慧輔助駕駛中的高效應用提供了基礎設施支撐。
世界模型四項突破 夯實智慧輔助駕駛倣真與安全基座
世界模型是此次理想汽車論文入選最為集中的領域,共有4篇論文入選,覆蓋深度估計、三維重建、認知評估與安全預判四大方向。InfiniDepth論文針對傳統深度估計中離散網格表示解析度受限、難以恢復精細幾何細節的行業痛點,創新性地將深度建模為神經隱式場,支持任意解析度的連續稠密深度查詢,在精細細節區域和度量深度估計上均表現優異,為新視角合成提供了更為精確的幾何先驗,有效提升大基線場景下的渲染品質。
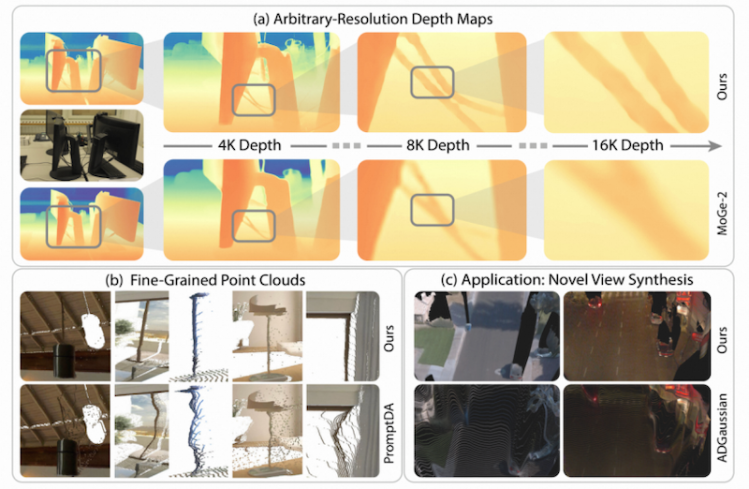
InfiniDepth
Unposed-to-3D論文聚焦于智慧輔助駕駛倣真對高品質三維車輛資産的迫切需求。針對現有方法依賴合成數據訓練且需要精確相機位姿標注、與真實場景存在域差距的問題,該研究提出兩階段框架,通過相機預測頭結合可微渲染實現無位姿圖像的自監督學習,最終從真實駕駛圖像中直接重建出尺度準確、外觀和諧的倣真就緒三維車輛,顯著降低了倣真資産的生産門檻。
DriveCombo論文揭示了當前多模態大語言模型在複雜交通規則理解上的真實能力邊界。現有基準僅覆蓋單一規則場景,無法反映真實駕駛中多規則併發與衝突的推理難度。該研究構建了文本與視覺雙模態基準,提出五級認知階梯,覆蓋從單規則理解到衝突消解的全認知鏈路,對14個主流模型的評估揭示了任務複雜度與性能下降之間的系統性規律,並驗證了該基準對提升下游規劃能力的實際價值。
AD-R1入選CVPR Findings,該論文致力於解決將強化學習應用於端到端智慧輔助駕駛時的核心障礙——世界模型因僅在安全專家數據上訓練而存在系統性樂觀偏差,面對危險軌跡時傾向於預測虛假的安全結果。該研究提出反事實合成流水線,將世界模型訓練為公正的因果預測器,並將其整合進閉環強化學習框架作為危險感知評論器,有效降低了倣真場景中的安全違規率,為智慧輔助駕駛的安全可靠性提供了新的技術路徑。
認知對齊與語言、視覺智慧 讓推理更準更快
在認知模型領域,當前基於視覺語言模型的方法逐幀處理獨立圖像的方案,缺乏對歷史狀態的顯式建模,導致決策抖動頻繁。CogDriver論文研究提出認知慣性機制,通過構建大規模敘事式視覺—語言—動作數據集提供時序監督信號,並設計帶有稀疏時序記憶模組的智慧體架構,結合時空知識蒸餾顯式訓練決策一致性,在Bench2Drive和nuScenes基準上分別實現22%的駕駛得分提升和21%的軌跡誤差降低,進一步解決了智慧輔助駕駛規劃中的時序一致性難題。
LinkVLA論文則聚焦于視覺語言動作模型中語言指令與動作輸出不匹配、自回歸動作生成效率低下兩大痛點。該研究通過結構連接將語言和動作特徵統一編入共享離散碼本,從底層強制實現跨模態一致性;同時引入“動作理解”輔助任務促進語言與動作的雙向映射,並採用粗到細的兩步法替代傳統逐步解碼。閉環自動駕駛基準測試表明,LinkVLA在顯著提升指令遵循準確性和駕駛性能的同時,節省了86%的推理延遲。
在語言智慧領域,FastMMoE入選CVPR Findings,該論文提出一套面向基於MoE(混合專家)架構的多模態大模型、無需重新訓練的加速優化框架,為多模態大模型的高效部署提供了新的技術路徑。針對多模態大模型計算開銷大、部署效率受限的行業痛點,FastMMoE從路由行為分析切入,融合視覺Token專家激活精簡與路由感知式Token剪枝兩套互補方案,在不犧牲核心能力的前提下大幅削減冗余計算。基於DeepSeek-VL2、InternVL3.5等主流模型的驗證實驗表明,FastMMoE最高可削減55%的浮點運算量,同時保留95.5%的原始性能,整體效果持續優於現有剪枝基線方法。
CoV-Align論文提出一種高效細粒度對齊框架,解決了多模態模型中圖像區域與語言描述精準匹配時計算效率低、特徵噪聲大的雙重難題。該研究創新性地提出“內聚視覺語義優先”策略,在不依賴文本引導的前提下,預先通過視覺信息自主聚合語義一致的圖像區域,從而實現高效精準的區域—單詞對齊。在Flickr30K和MS-COCO經典圖文評測基準上,CoV-Align取得當前最優性能,推理速度較前沿基線方法提升3至5倍,在大規模多模態任務中展現出突出的實用優勢。
在視覺智慧領域,Switch-KD入選CVPR Findings,用一套跨模態知識新蒸餾範式以小博大,讓0.5B的小模型擁有了逼近1.5B模型的多模態理解力。該方法突破了傳統蒸餾“模態分離監督”的瓶頸,徹底重構了跨模態知識蒸餾的底層邏輯——從“各管一段”的模態分離監督,轉向統一概率空間蒸餾,為車端邊緣計算、智慧座艙等輕量化部署場景提供了關鍵技術支撐。
理想汽車始終將基礎研究視為支撐長期發展的核心動力。截至2026年一季度末,理想汽車已連續5個季度保持30億元左右的高強度研發投入,並連續6年持續加碼研發投入。2025年全年研發費用達到113億元,為歷史新高。近5年,理想汽車圍繞多模態感知、端到端、認知模型、世界模型、強化學習和基座模型等核心技術方向,在CVPR、ICCV、ECCV、NeurIPS、SIGGRAPH、IROS、ICRA等頂級學術會議和期刊上發表近百篇論文,持續印證理想汽車技術研究的前沿性和影響力。
在基礎研究過程中,理想汽車積極與國內外高校展開闔作,踐行“産學研結合”的創新模式,將自身在實際應用中積累的數據和工程經驗反饋學術研究,推動産學研互利共贏。理想汽車的每一項研究成果和技術突破都指向同一個目標:以更強的技術積累兌現“給車和家賦予生命”的品牌使命,讓每個家庭都能享受到智慧科技帶來的便利。未來,理想汽車將持續加大基礎研究與應用創新的投入,以紮實的技術積累和開放的生態理念,邁向全球領先的具身智慧企業。(資料來源:理想汽車)



1、“國際在線”由中國國際廣播電台主辦。經中國國際廣播電台授權,國廣國際在線網絡(北京)有限公司獨家負責“國際在線”網站的市場經營。
2、凡本網註明“來源:國際在線”的所有信息內容,未經書面授權,任何單位及個人不得轉載、摘編、複製或利用其他方式使用。
3、“國際在線”自有版權信息(包括但不限于“國際在線專稿”、“國際在線消息”、“國際在線XX消息”“國際在線報道”“國際在線XX報道”等信息內容,但明確標注為第三方版權的內容除外)均由國廣國際在線網絡(北京)有限公司統一管理和銷售。
已取得國廣國際在線網絡(北京)有限公司使用授權的被授權人,應嚴格在授權範圍內使用,不得超範圍使用,使用時應註明“來源:國際在線”。違反上述聲明者,本網將追究其相關法律責任。
任何未與國廣國際在線網絡(北京)有限公司簽訂相關協議或未取得授權書的公司、媒體、網站和個人均無權銷售、使用“國際在線”網站的自有版權信息産品。否則,國廣國際在線網絡(北京)有限公司將採取法律手段維護合法權益,因此産生的損失及為此所花費的全部費用(包括但不限于律師費、訴訟費、差旅費、公證費等)全部由侵權方承擔。
4、凡本網註明“來源:XXX(非國際在線)”的作品,均轉載自其它媒體,轉載目的在於傳遞更多信息,豐富網絡文化,此類稿件並不代表本網贊同其觀點和對其真實性負責。
5、如因作品內容、版權和其他問題需要與本網聯繫的,請在該事由發生之日起30日內進行。



